Understanding Large Language Model Behaviors through
Interactive Counterfactual Generation and Analysis






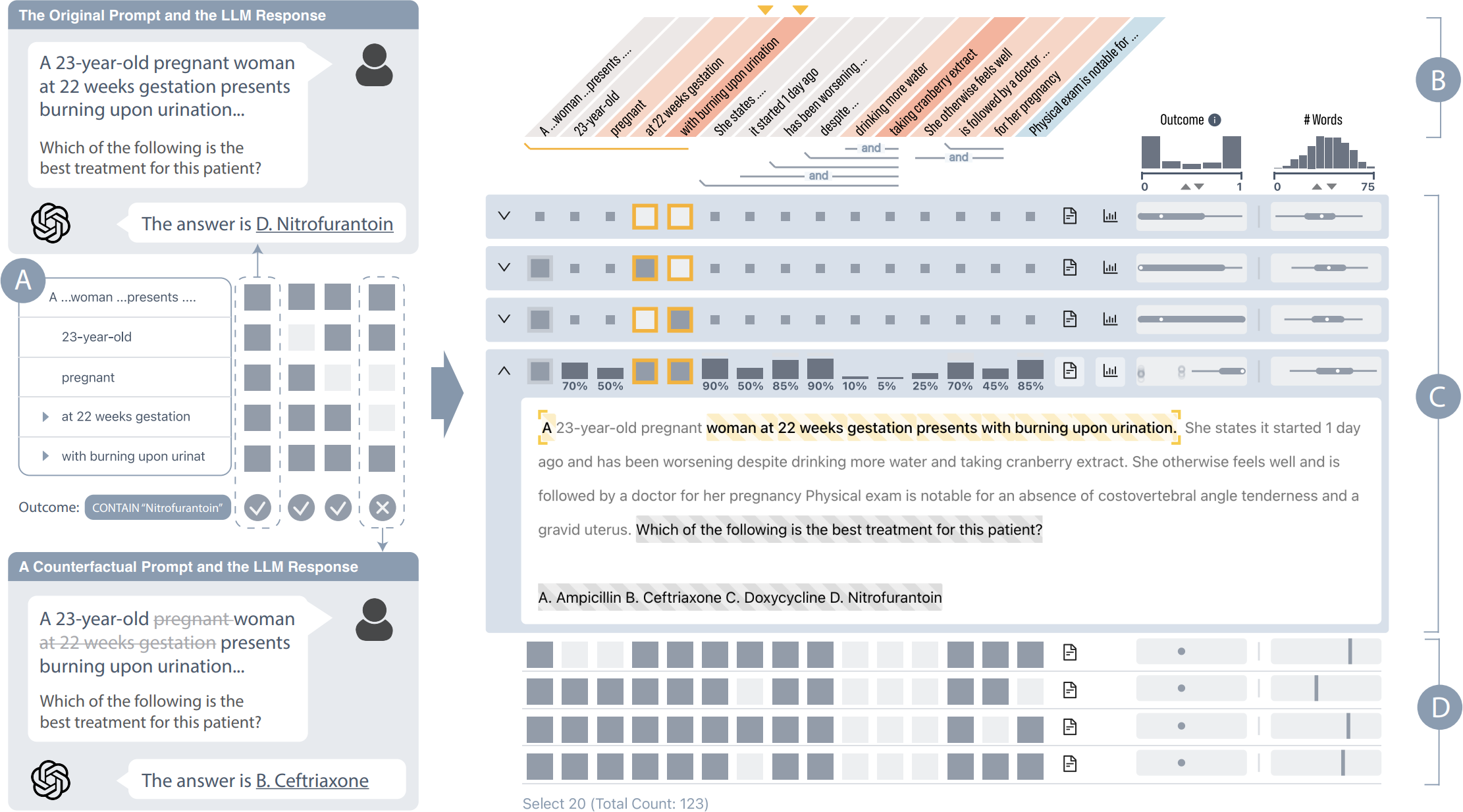
Abstract
Understanding the behavior of large language models (LLMs) is crucial for ensuring their safe and reliable use. However, existing explainable AI (XAI) methods for LLMs primarily rely on word-level explanations, which are often computationally inefficient and misaligned with human reasoning processes. Moreover, these methods often treat explanation as a one-time output, overlooking its inherently interactive and iterative nature. In this paper, we present LLM Analyzer, an interactive visualization system that addresses these limitations by enabling intuitive and efficient exploration of LLM behaviors through counterfactual analysis. Our system features a novel algorithm that generates fluent and semantically meaningful counterfactuals via targeted removal and replacement operations at user-defined levels of granularity. These counterfactuals are used to compute feature attribution scores, which are then integrated with concrete examples in a table-based visualization, supporting dynamic analysis of model behavior. A user study with LLM practitioners and interviews with experts demonstrate the system's usability and effectiveness, emphasizing the importance of involving humans in the explanation process as active participants rather than passive recipients.
Motivation
Large Language Models (LLMs) have shown remarkable capabilities in interpreting textual instructions and solving complex tasks. As their adoption grows across a wide range of applications, understanding how and why these models generate specific outputs becomes increasingly critical for ensuring their safety and reliability. To this end, developing methods that enhance transparency and help users better understand the behavior and limitations of the model is essential.
Existing eXplainable Artificial Intelligence (XAI) approaches for interpreting local model behavior, such as feature attribution methods, primarily provide static, one-shot explanations. While these methods can be informative in certain contexts, they suffer from two major limitations. First, explanation is inherently an interactive and iterative process: users often seek to ask follow-up questions, test new hypotheses about model behavior, and progressively refine their understanding. Static and monolithic explanations do not accommodate this natural exploratory workflow. Second, these methods typically operate at the word level, such as quantifying the influence of individual tokens on the model's prediction. However, word-level representations cause unnecessarily long running time for certain algorithms, including most of the commonly-used removal-based methods, and fail to capture the semantic units that humans use for reasoning. Humans generally interpret and explain decisions in terms of higher-level meanings, such as phrases, propositions, or claims, rather than isolated words.
Our Contributions
- LLM Analyzer, an interactive visualization tool to support LLM practitioners and domain experts in understanding LLM behaviors by analyzing meaningful counterfactuals
- A time-efficient algorithm for generating grammatically correct and syntactic-structure-preserving counterfactuals via removing and replacing text segments in user-defined granularity
- A user study and expert interviews, providing useful insights into the usage of the system in understanding LLM behaviors
Background
Large Language Models (LLMs) have shown remarkable capabilities in interpreting textual instructions and solving complex tasks. As their adoption grows across a wide range of applications, understanding how and why these models generate specific outputs becomes increasingly critical for ensuring their safety and reliability. The challenge of explainability in this context involves helping users develop accurate mental models of how a machine learning model behaves, enabling them to evaluate whether its behavior aligns with their knowledge and values.
Related Work
Existing XAI approaches for understanding model behavior include feature attribution methods, counterfactual explanations, and anchor methods. Feature attribution methods use additive models to describe an ML model's local behaviors and quantify the influences of each feature to the prediction, helping answer Why and Why not questions. Removal-based methods, represented by LIME and KernelSHAP, are widely used because they are model-agnostic. Counterfactual explanations are one of the most commonly used example-based explanation methods, defined as counterfactuals with a minimal difference from the original instance, leading to a different prediction. The Anchor method uses rules to find sufficient conditions for model prediction. However, these methods provide partial insights and position users as passive recipients of unified, static explanations, overlooking the inherently interactive and iterative nature of explanation.
Methodology
Our approach consists of a computational pipeline that constructs interpretable representations of text and performs perturbations to generate meaningful counterfactuals. The pipeline leverages the sentence's dependency syntax to determine whether pairs of words should be grouped together, segmenting the input sentence into interpretable components. This forms a simplified representation of the sentence as a binary vector. Based on this interpretable representation, the algorithm systematically generates all meaningful removal-based counterfactuals by selectively removing or replacing specific segments. By evaluating model predictions on these counterfactuals, the system quantifies the influence of each input component on the model's prediction through KernelSHAP aggregation. The resulting attribution scores are visualized to support user exploration and understanding.
Evaluation
We evaluate LLM Analyzer through a hypothetical use case, a user study, and feedback from XAI and NLP experts. In the user study with eight participants, we explored how users interact with the system when interpreting LLM behaviors and evaluated its usability and usefulness. Participants found the system easy to use and useful for understanding LLM behaviors, particularly when exploring what-if scenarios and addressing How to be questions. Additionally, we conducted interviews with three NLP researchers and three XAI researchers, each with between three and over ten years of experience. Experts from both domains found the system design to be concise and easy to comprehend, presenting a comprehensive overview of numerous functionalities.
Discussion
Based on feedback from both users and experts, we outline two directions for future research and discuss the limitations of our system. The explanation process is inherently interactive, evolving through a dynamic exchange between the explainer and the explainee. A deeper understanding of this process can inform the development of more effective explanation tools that enhance both explanatory efficiency and user experience. For free-form text generation tasks, such as creative writing or complex reasoning, defining appropriate evaluators becomes much more challenging. We believe that logic-based evaluators offer a promising solution in these cases, as they are more general and better equipped to handle the variability inherent in natural language.
Conclusion
This paper presents LLM Analyzer, an interactive visualization system with an efficient counterfactual generation algorithm designed to support LLM practitioners and users in understanding LLM behaviors. The system facilitates interactive counterfactual generation and analysis, enabling users to actively engage in the exploration of LLM responses by varying target instances and analyzing outcomes at customizable levels of granularity. We conducted experiments demonstrating that our counterfactual generation algorithm is both time-efficient and capable of producing high-quality counterfactuals. Additionally, a user study and expert interviews with professionals in NLP and XAI validate the system's usability and usefulness. Our findings underscore the importance of involving humans as active participants in the explanation process, rather than as passive recipients of explanations.
Links to External Sources
References
- Arawjo, I., Swoopes, C., Vaithilingam, P., Wattenberg, M., and Glassman, E. L. ChainForge: A Visual Toolkit for Prompt Engineering and LLM Hypothesis Testing. In CHI '24: Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pp. 1–18. ACM, Honolulu, 2024. DOI: 10.1145/3613904 🔗.3642016
- Brath, R., Keim, D., Knittel, J., Pan, S., Sommerauer, P., and Strobelt, H. The Role of Interactive Visualization in Explaining (Large) NLP Models: From Data to Inference, 2023. DOI: 10.48550/arXiv 🔗.2301.04528
- Brooke, J. SUS-A Quick and Dirty Usability Scale in Usability Evaluation in Industry. Taylor & Francis, 1996. DOI: 10.1201/9781498710411 🔗
- Cheng, F., Ming, Y., and Qu, H. DECE: Decision Explorer with Counterfactual Explanations for Machine Learning Models. IEEE Transactions on Visualization and Computer Graphics, 27:1438–1447, 2021. DOI: 10.1109/TVCG 🔗.2020.3030342
- Cheng, F., Zouhar, V., Arora, S., Sachan, M., Strobelt, H., and El-Assady, M. RELIC: Investigating Large Language Model Responses using Self-Consistency. In CHI '24: Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pp. 1–18. ACM, Honolulu, 2024. DOI: 10.1145/3613904 🔗.3641904
- Coscia, A. and Endert, A. KnowledgeVIS: Interpreting Language Models by Comparing Fill-in-the-Blank Prompts. IEEE Transactions on Visualization and Computer Graphics, 30:6520–6532, 2024. DOI: 10.1109/TVCG 🔗.2023.3346713
- Coscia, A., Holmes, L., Morris, W., Choi, J. S., Crossley, S., and Endert, A. iScore: Visual Analytics for Interpreting How Language Models Automatically Score Summaries. In Proceedings of the 29th International Conference on Intelligent User Interfaces, pp. 787–802. ACM, Greenville, 2024. DOI: 10.1145/3640543 🔗.3645142
- Covert, I., Lundberg, S., and Lee, S.-I. Explaining by removing: A unified framework for model explanation. Journal of Machine Learning Research, 22:1–90, 2021.
- Desmond, M., Ashktorab, Z., Pan, Q., Dugan, C., and Johnson, J. M. EvaluLLM: LLM assisted evaluation of generative outputs. In Companion Proceedings of the 29th International Conference on Intelligent User Interfaces, pp. 30–32. ACM, Greenville, 2024. DOI: 10.1145/3640544 🔗.3645216
- Doshi-Velez, F. and Kim, B. Towards A Rigorous Science of Interpretable Machine Learning, 2017. DOI: 10.48550/ARXIV 🔗.1702.08608
- Fabbri, A., Li, I., She, T., Li, S., and Radev, D. Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 1074–1084. ACL, Florence, 2019. DOI: 10.18653/v1/P19-1102 🔗
- Kahneman, D. and Tversky, A. The simulation heuristic. In D. Kahneman, P. Slovic, and A. Tversky, eds., Judgment under Uncertainty, pp. 201–208. Cambridge University Press, 1982. DOI: 10.1017/CBO9780511809477 🔗.015
- Kahng, M., Tenney, I., Pushkarna, M., Liu, M. X., Wexler, J., Reif, E., Kallarackal, K., Chang, M., Terry, M., and Dixon, L. LLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models. In CHI EA '24: Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pp. 1–7. ACM, Honolulu, 2024. DOI: 10.1145/3613905 🔗.3650755
- Kaushik, D., Hovy, E., and Lipton, Z. C. Learning the Difference that Makes a Difference with Counterfactually-Augmented Data. International Conference on Learning Representations, 2020.
- Kornilova, A. and Eidelman, V. BillSum: A Corpus for Automatic Summarization of US Legislation. In Proceedings of the 2nd Workshop on New Frontiers in Summarization, pp. 48–56. ACL, Hong Kong, 2019. DOI: 10.18653/v1/D19-5406 🔗
- Lee, S. Y.-T., Bahukhandi, A., Liu, D., and Ma, K.-L. Towards Dataset-Scale and Feature-Oriented Evaluation of Text Summarization in Large Language Model Prompts. IEEE Transactions on Visualization and Computer Graphics, 31:481–491, 2025. DOI: 10.1109/TVCG 🔗.2024.3456398
- Lewis, D. Counterfactuals. Blackwell, 1973.
- Lex, A., Gehlenborg, N., Strobelt, H., Vuillemot, R., and Pfister, H. UpSet: Visualization of Intersecting Sets. IEEE Transactions on Visualization and Computer Graphics, 20:1983–1992, 2014. DOI: 10.1109/TVCG 🔗.2014.2346248
- Liao, Q. V., Gruen, D., and Miller, S. Questioning the AI: Informing Design Practices for Explainable AI User Experiences. In CHI '20: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pp. 1–15. ACM, Honolulu, 2020. DOI: 10.1145/3313831 🔗.3376590
- Liao, Q. V. and Varshney, K. R. Human-Centered Explainable AI (XAI): From Algorithms to User Experiences, 2021. DOI: 10.48550/ARXIV 🔗.2110.10790
- Lundberg, S. M. and Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, vol. 30, pp. 1–10. Curran Associates Inc., Long Beach, 2017.
- Madaan, N., Padhi, I., Panwar, N., and Saha, D. Generate Your Counterfactuals: Towards Controlled Counterfactual Generation for Text. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 13516–13524. Online, 2021. DOI: 10.1609/aaai 🔗.v35i15.17594
- Maia, M., Handschuh, S., Freitas, A., Davis, B., McDermott, R., Zarrouk, M., and Balahur, A. WWW'18 Open Challenge: Financial Opinion Mining and Question Answering. In WWW '18: Companion Proceedings of the The Web Conference 2018, pp. 1941–1942. ACM, Lyon, 2018. DOI: 10.1145/3184558 🔗.3192301
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence, 267:1–38, 2019. DOI: 10.1016/j 🔗.artint.2018.07.007
- Ming, Y., Cao, S., Zhang, R., Li, Z., Chen, Y., Song, Y., and Qu, H. Understanding Hidden Memories of Recurrent Neural Networks. In IEEE Conference on Visual Analytics Science and Technology, pp. 13–24. IEEE, Phoenix, 2017. DOI: 10.1109/VAST 🔗.2017.8585721
- Morgan, S. L. and Winship, C. Counterfactuals and Causal Inference: Methods and Principles for Social Research. Cambridge University Press, 2014. DOI: 10.1017/CBO9781107587991 🔗
- Pham, Nam. tiny-textbooks (revision 14de7ba), 2023. DOI: 10.57967/hf/1126 🔗
- Nobre, C., Streit, M., and Lex, A. Juniper: A Tree+Table Approach to Multivariate Graph Visualization. IEEE Transactions on Visualization and Computer Graphics, 25:544–554, 2019. DOI: 10.1109/TVCG 🔗.2018.2865149
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. In Proceedings of the 36th International Conference on Neural Information Processing Systems, vol. 35, pp. 27730–27744. Curran Associates Inc., New Orleans, 2022.
- Pearl, J. Causal inference in statistics: An overview. Statistics Surveys, 3:96–146, 2009. DOI: 10.1214/09-SS057 🔗
- Ribeiro, M. T., Singh, S., and Guestrin, C. "Why Should I Trust You?": Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1135–1144. ACM, San Francisco, 2016. DOI: 10.1145/2939672 🔗.2939778
- Ribeiro, M. T., Singh, S., and Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32, pp. 1527–1535. New Orleans, 2018. DOI: 10.1609/aaai 🔗.v32i1.11491
- Ribeiro, M. T., Wu, T., Guestrin, C., and Singh, S. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4902–4912. ACL, Online, 2020. DOI: 10.18653/v1/2020 🔗.acl-main.442
- Robeer, M., Bex, F., and Feelders, A. Generating Realistic Natural Language Counterfactuals. In Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 3611–3625. ACL, Punta Cana, 2021. DOI: 10.18653/v1/2021 🔗.findings-emnlp.306
- Shao, Z., Sun, S., Zhao, Y., Wang, S., Wei, Z., Gui, T., Turkay, C., and Chen, S. Visual Explanation for Open-Domain Question Answering With BERT. IEEE Transactions on Visualization and Computer Graphics, 30:3779–3797, 2024. DOI: 10.1109/TVCG 🔗.2023.3243676
- Spinner, T., Kehlbeck, R., Sevastjanova, R., Stähle, T., Keim, D. A., Deussen, O., and El-Assady, M. -generAItor: Tree-in-the-loop Text Generation for Language Model Explainability and Adaptation. ACM Transactions on Interactive Intelligent Systems, 14:1–32, 2024. DOI: 10.1145/3652028 🔗
- Strobelt, H., Gehrmann, S., Behrisch, M., Perer, A., Pfister, H., and Rush, A. M. Seq2seq-Vis: A Visual Debugging Tool for Sequence-to-Sequence Models. IEEE Transactions on Visualization and Computer Graphics, 25:353–363, 2019. DOI: 10.1109/TVCG 🔗.2018.2865044
- Strobelt, H., Gehrmann, S., Pfister, H., and Rush, A. M. LSTMVis: A Tool for Visual Analysis of Hidden State Dynamics in Recurrent Neural Networks. IEEE Transactions on Visualization and Computer Graphics, 24:667–676, 2018. DOI: 10.1109/TVCG 🔗.2017.2744158
- Tenney, I., Wexler, J., Bastings, J., Bolukbasi, T., Coenen, A., Gehrmann, S., Jiang, E., Pushkarna, M., Radebaugh, C., Reif, E., and Yuan, A. The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 107–118. ACL, Online, 2020. DOI: 10.18653/v1/2020 🔗.emnlp-demos.15
- Thirunavukarasu, A. J., Hassan, R., Mahmood, S., Sanghera, R., Barzangi, K., El Mukashfi, M., and Shah, S. Trialling a Large Language Model (ChatGPT) in General Practice With the Applied Knowledge Test: Observational Study Demonstrating Opportunities and Limitations in Primary Care. JMIR Medical Education, 9:1–9, 2023. DOI: 10.2196/46599 🔗
- Wachter, S., Mittelstadt, B., and Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harvard Journal of Law and Technology, 31:841–887, 2017.
- Wang, A. Z., Borland, D., and Gotz, D. An empirical study of counterfactual visualization to support visual causal inference. Information Visualization, 23:197–214, 2024. DOI: 10.1177/14738716241229437 🔗
- Wang, X., Huang, R., Jin, Z., Fang, T., and Qu, H. CommonsenseVIS: Visualizing and Understanding Commonsense Reasoning Capabilities of Natural Language Models. IEEE Transactions on Visualization and Computer Graphics, 30:273–283, 2024. DOI: 10.1109/TVCG 🔗.2023.3327153
- Wang, Z. J., Turko, R., and Chau, D. H. Dodrio: Exploring Transformer Models with Interactive Visualization. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, pp. 132–141. ACL, Online, 2021. DOI: 10.18653/v1/2021 🔗.acl-demo.16
- Wexler, J., Pushkarna, M., Bolukbasi, T., Wattenberg, M., Viegas, F., and Wilson, J. The What-If Tool: Interactive Probing of Machine Learning Models. IEEE Transactions on Visualization and Computer Graphics, 26:56–65, 2020. DOI: 10.1109/TVCG 🔗.2019.2934619
- Wu, T., Ribeiro, M. T., Heer, J., and Weld, D. Polyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 6707–6723. ACL, Online, 2021. DOI: 10.18653/v1/2021 🔗.acl-long.523
- Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W., Salakhutdinov, R., and Manning, C. D. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2369–2380. ACL, Brussels, 2018. DOI: 10.18653/v1/D18-1259 🔗
- Yeh, C., Chen, Y., Wu, A., Chen, C., Viégas, F., and Wattenberg, M. AttentionViz: A Global View of Transformer Attention. IEEE Transactions on Visualization and Computer Graphics, 30:262–272, 2023. DOI: 10.1109/TVCG 🔗.2023.3327163